Redundant Array of Inexpensive Disks (RAID)


RAID in Linux can be used to create logical volumes to ensure recovery from disk failures, backups, etc.
What is RAID?
RAID “redundant array of inexpensive disks” or “redundant array of independent disks” is a data storage virtualization technology that combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both.
Data redundancy refers to the practice of keeping data in two or more places within a database or data storage system.
RAID Configurations
You can set up and use two categories of RAIDs. These are –
- Hardware RAID
- Software RAID
Hardware-based RAID requires a dedicated controller to be installed on the server. RAID controllers in hardware are configured through card basic I/O system or Option ROM (read-only memory) either before or after the OS is booted.
Software-based RAID is provided by several modern Operating Systems. It is implemented in a number of ways, including as a component of the file system; as a layer that abstracts devices as a single virtual device; and as a layer that sits above any file system. This method of RAID uses some of the system’s computing power to manage a software-based RAID configuration.
RAID Levels
RAID devices use different versions, called levels. The original paper that coined the term and developed the RAID setup concept defined six levels of RAID — 0 through 5. This numbered system enabled those in IT to differentiate RAID versions. The number of levels has since expanded and has been broken into three categories: standard, nested, and nonstandard RAID levels.
RAIDs are in various Levels. Some of the most used RAID levels are:
- RAID 0: Striping
- RAID 1: Mirroring
- RAID 5: Single Disk Distributed Parity
- RAID 6: Double Disk Distributed Parity
- RAID 10: Combine of Mirror & Stripe. (Nested RAID)
RAID 0: This configuration has striping but no redundancy of data. It offers the best performance, but it does not provide fault tolerance.
Stripe is sharing data randomly to multiple disks. If we use 2 disks half of our data will be in each disk.
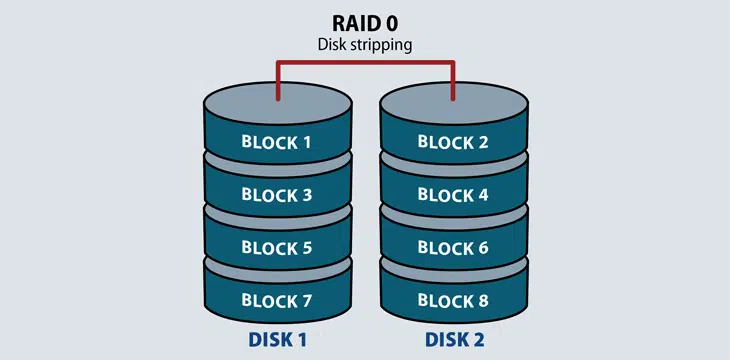
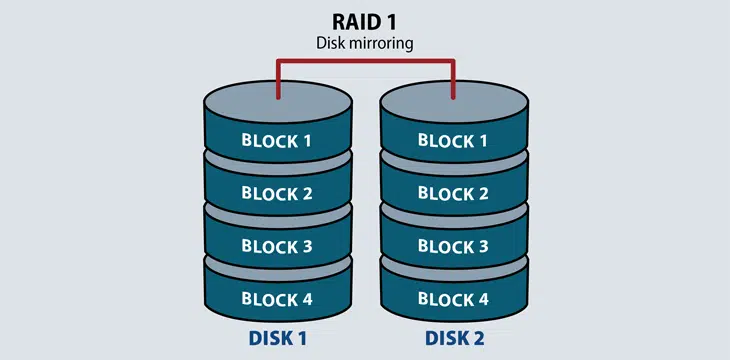
RAID 1: Also known as disk mirroring, this configuration consists of at least two drives that duplicate the storage of data. There is no striping. Read performance is improved, since either disk can be read at the same time. RAID1 requires a minimum of 2 drives.
Mirroring is making a copy of the same data. In RAID 1 it will save the same content to the other disk too.
RAID 5: This level is based on parity block-level striping. The parity information is striped across each drive, enabling the array to function, even if one drive were to fail. This will protect our data from drive failure. Better performance than that of a single drive, but not as high as a RAID 0 array. RAID 5 requires at least three disks. RAID5 can survive from single disk failures but in case of multiple disk failure data loss may occur.
Parity method in raid regenerate the lost content from parity’s saved information.
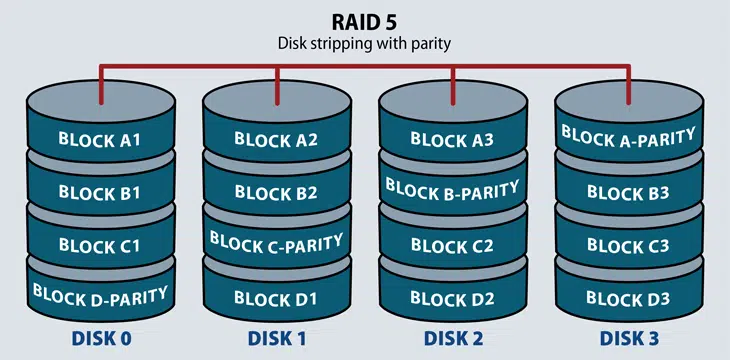
If we have 4 numbers of 1TB hard-drive. The parity information will be stored in 256GB in each drive and 768GB in each drive will be defined for Users.
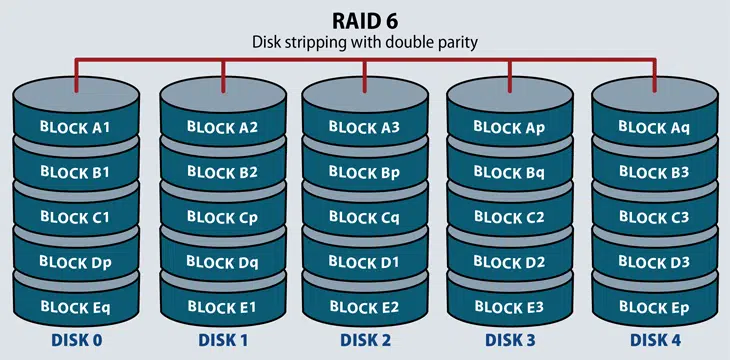
RAID 6: This technique is similar to RAID 5, but it includes a second parity scheme distributed across the drives in the array. The use of additional parity enables the array to continue functioning, even if two disks fail simultaneously. However, this extra protection comes at a cost. RAID 6 arrays often have slower write performance than RAID 5 arrays.
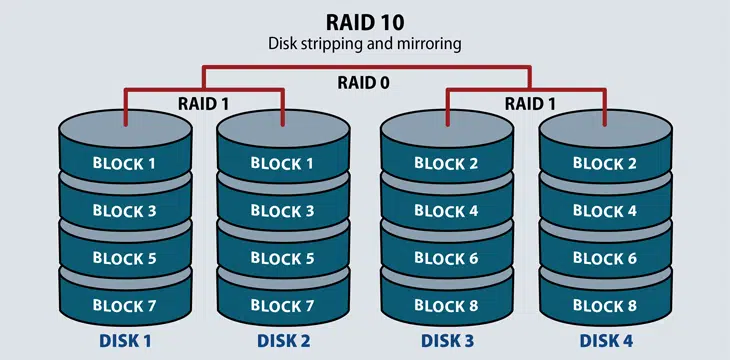
RAID 10 (RAID 1+0): Combining RAID 1 and RAID 0, this level is often referred to as RAID 10, which offers higher performance than RAID 1. In RAID 1+0, the data is mirrored, and the mirrors are striped.
Benefits of RAID
There are several benefits of implementing RAID in Linux at various levels. The following are the primary benefits:
- Redundancy: If one disk crashes, the data is duplicated on other disks, preventing data loss.
- Performance: By writing data to several disks, the overall data transfer rate can be increased.
- Convenience: Setting up RAID is simpler, and storage from several physical disks can be handled even though they are in different systems.
- Parity Check: This feature can check for any potential system crashes and warn you.
Wrap up
The above content provides basic understanding about RAID. In this article we have seen what RAID is and which levels are mostly used in RAID. For setting up RAID one must know the basics of RAID.